Stage 1: Data Pre-processing
Select Data
It is necessary to understand the context of each dataset to allow a representative conversion to be performed.
- Meet with Data Owner
- Discuss their dataset(s) and specific requirements.
- Understand what each dataset represents (so you understand their context and perspectives).
- Explain the data engineering process (so they understand your perspective and what Health Informatics can offer).
- Choose Data Set(s)
- Discuss with the data owner which dataset(s) they would like converted.
- Select data and conversion goals:
- The aim is ‘Data Discoverability’.
- Define conversion goals, i.e., what is to be converted for discoverability.
- Select data attributes to be converted – not all data attributes are necessary for discoverability, a minimal set of data attributes may just be necessary.
- Define Working processes
-
Understand where each dataset is located.
-
Understand what the security arrangements are.
-
Understand access rights to the dataset.
-
Define communication and feedback mechanisms and frequency thereof – these can be emails, weekly meetings, etc.
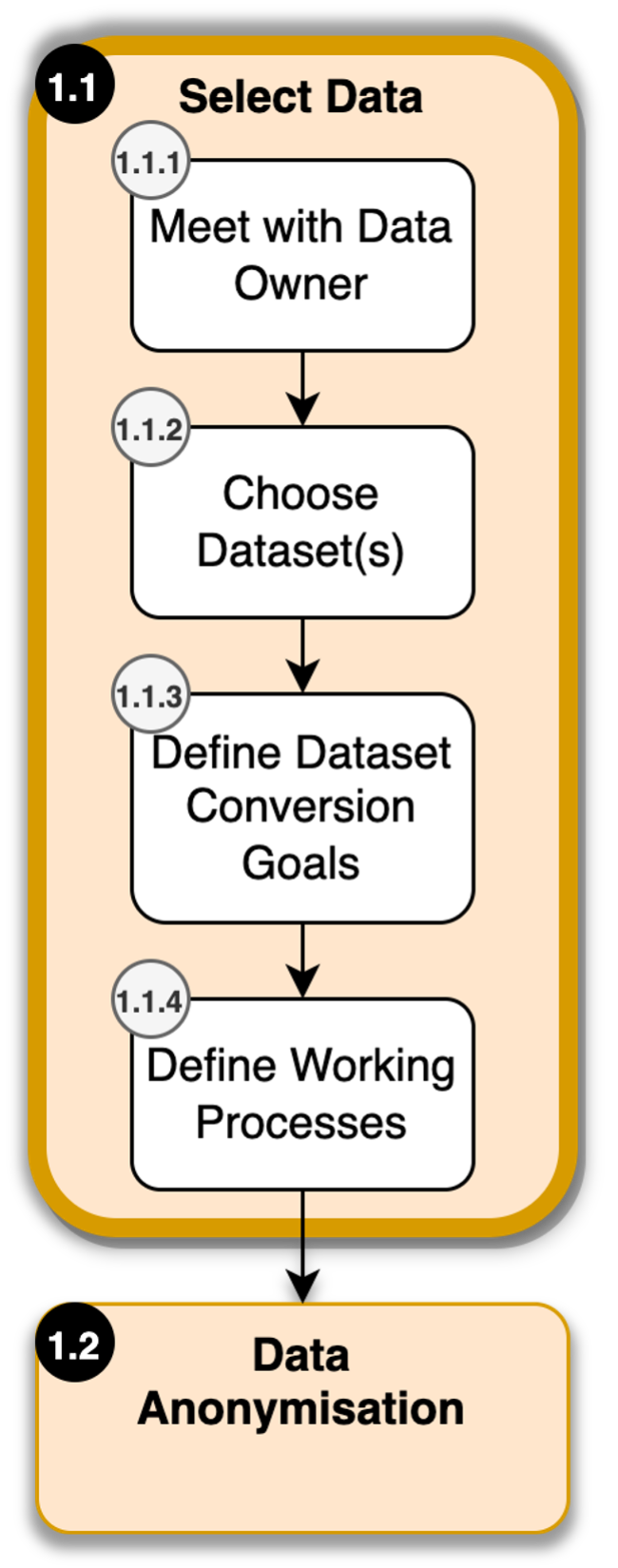
Figure 3: Selecting Data during Data Pre-processing
Data Anonymisation
The anonymisation of data is paramount, it is critical that the following steps are carefully followed.
It is the responsibility of the Data Owner to de-identify datasets before they are supplied for OMOP conversion.
- Define Data Anonymisation
- Identify the Personally identifiable information (PII) / Personal Data: data attributes (see PII definition and description).
- Locate and highlight the Direct-Identifier data.
- Locate and highlight the Pseudo-Identifier data.
- Discuss with Data Owner which Pseudo-Identifier data should be removed (see PII definition and description) – Date of Birth must be removed!
- Anonymise dataset
-
It is the responsibility of the Data Owner to de-identify datasets!
-
Direct identifier data ‘must be removed’ from each dataset – remove the row data from the columns, do not delete the columns.
-
Remove agreed Pseudo-Identifier data – again, remove the row data, do not delete the columns.
- Date of Birth must be removed!
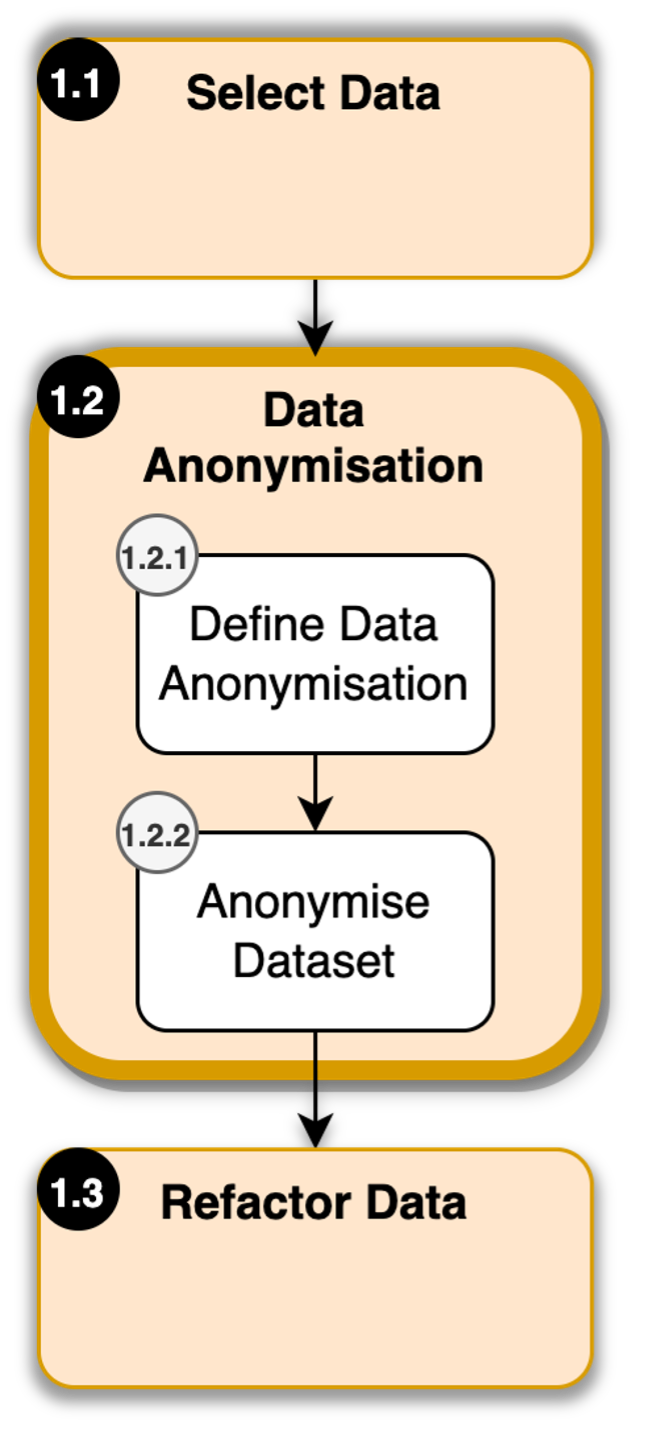
Figure 4: Data Anonymisation during Data Pre-processing
Personally Identifiable Information (PII) / Personal Data
This means any informaton relating to an identified or identifiable natural person (data subject); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person Information Commissioner’s Office.
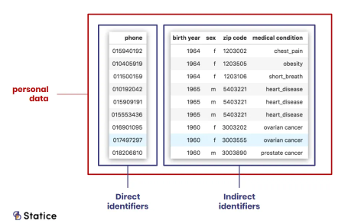
Figure 5: Example of Direct and Indirect Identifiers
PII refers to data that can be used to identify, locate, or contact individuals or establishments, or reveal the characteristics or other details about them. PII might consist of direct identifiers, such as the name, social security number or other information that is unique to an individual. Indirect identifiers include uncommon race, ethnicity, extreme age, unusual occupation and other details CDC.
Direct Identifiers
-
‘Direct identifiers are variables that point explicitly to particular individuals or units’ University of Tennessee.
-
‘Information that explicitly identifies a person’ Devaux.
Direct identifier data must be removed from datasets, as follows:

Figure 6: Example of Removing Direct Identifiers.
Indirect / Quasi-Identifiers
-
‘A quasi-identifier (also called a semi-key) is a subset of attributes which uniquely identifies most entities in the real world or tuples in a table’ Motwani and Xu, 2007.
-
‘Information that can be combined with additional data to identify a person’ Devaux, 2020.
The majority of quasi-identifier data must be removed, as follows:
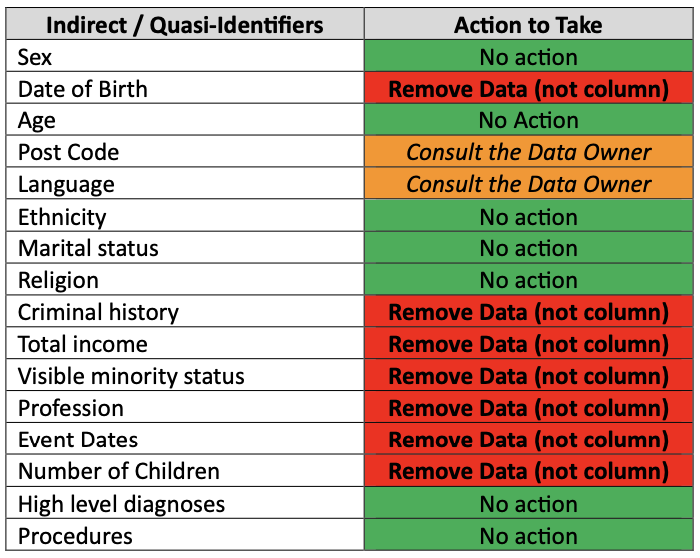
Figure 7: Example of Removing Indirect Identifiers.
Refactor Data
The anonymisation of data is paramount, it is critical that the following steps are carefully followed.
It is the responsibility of the Data Owner to de-identify datasets before they are supplied for OMOP conversion.
- Organise Data Tables
- Create a demographics table, consisting of:
- Identifier
- Date of Birth
- Sex at Birth
- Ethnicity
- The rest of the data can then be arranged as deemed fit by the data owner and / or the data team, each table must include:
- 1 x identifying column per table.
- 1 x date event per table.
- Create Dataset Extract
-
First, check the Data Standards page for exact requirements.
-
Extract the data from the data source – this can be done in 2 ways:
- export tables to CSV files (1 per table);
- create a view within the database.
-
Prepare a data dictionary for mapping.
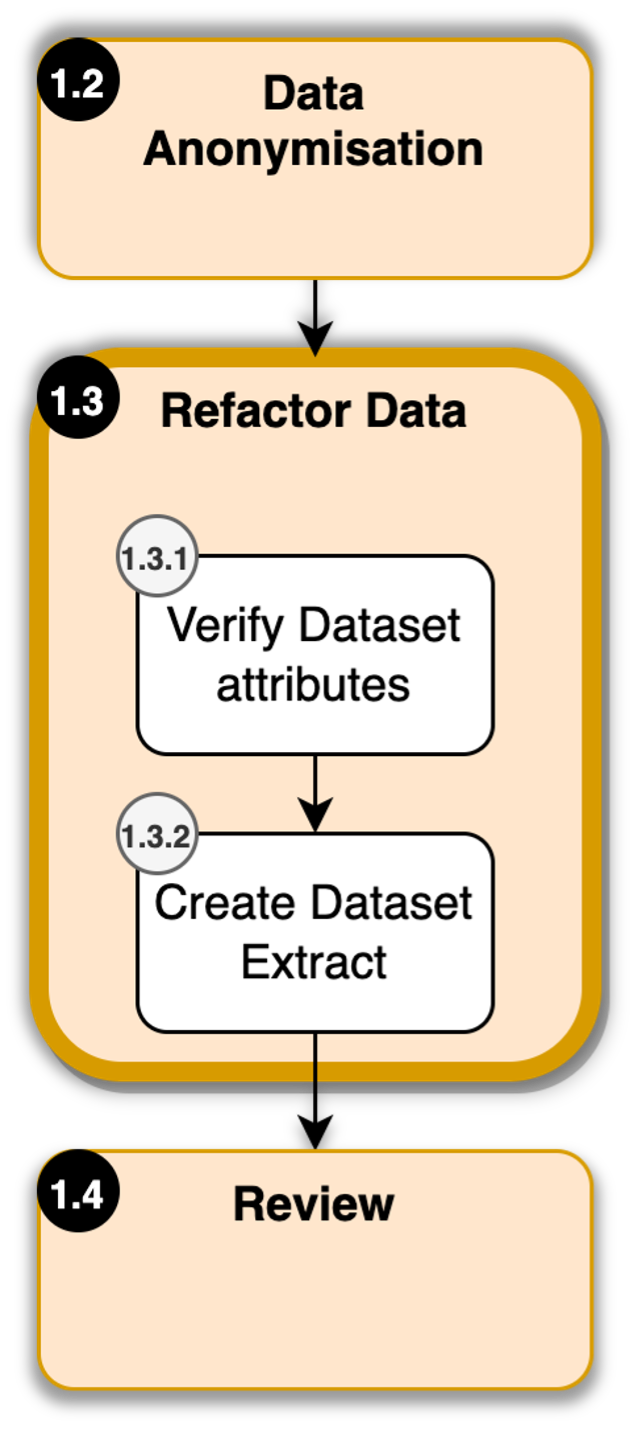
Figure 8: Refactoring the Data in Data Preprocessing.
Review
It is essential that all data extracts are reviewed prior to Stage 2.
- Review Dataset Extract
-
Check the agreed data attributes chosen in Stage 1 are selected.
-
Check that the dataset has been anonymised as per Stage 2.
-
Check the demographics table exists and contains these 4 data attributes:
- Identifier
- Date of Birth
- Sex
- Ethnicity
-
Check that there is a date event to map to per dataset table and that it conforms to Carrot Standards.
-
Check that there is a date event to map to per dataset table.
- CHECK WHETHER THE DATA DICTIONARY FOLLOWS OMOP DATA STANDARDS.
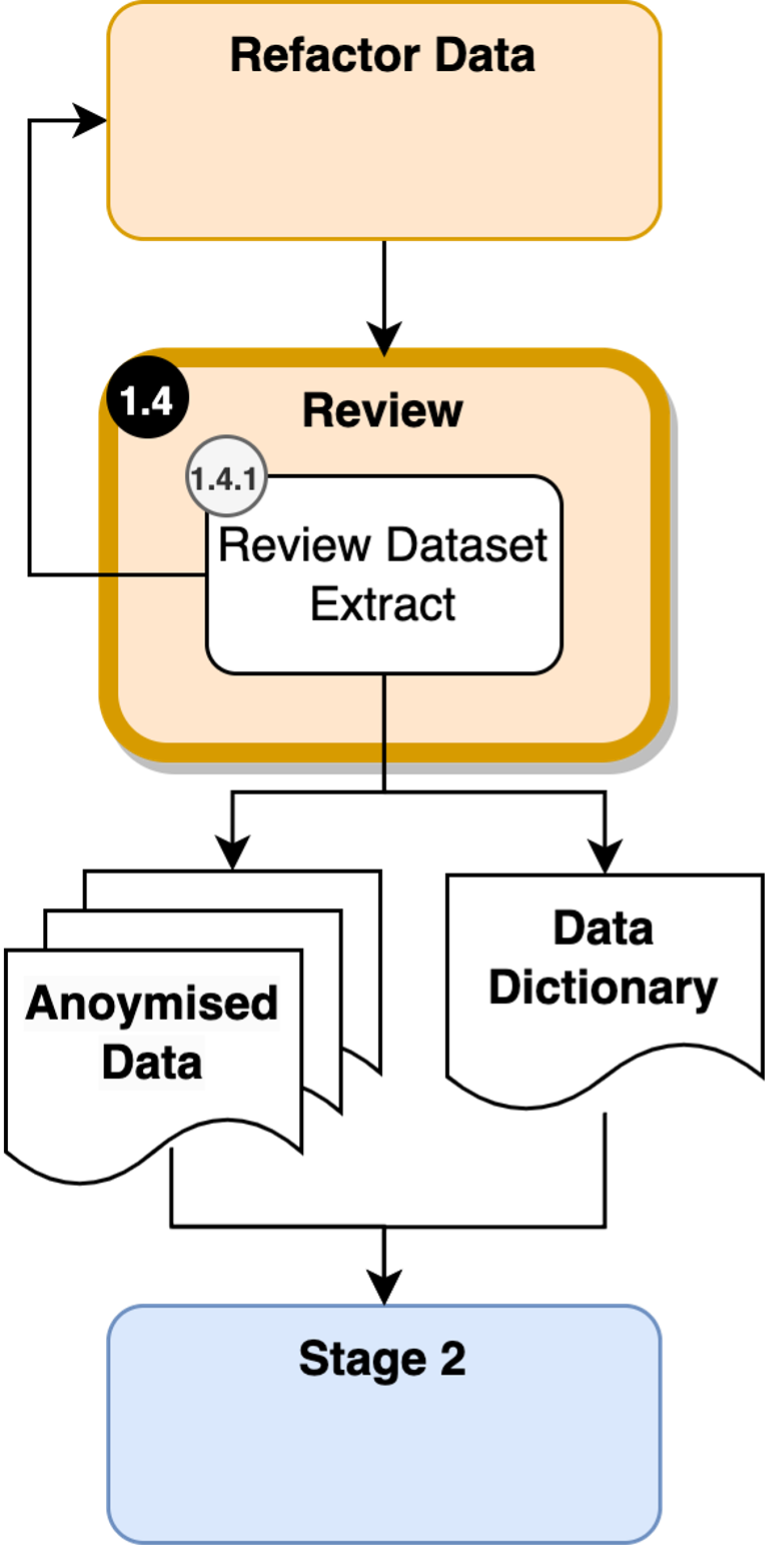
Figure 9: Reviewing in Data Preprocessing.